PALMテキスト生成モデルの紹介
PALMモデルは汎用的な预售訓練生成モデルであり、各種のダウンストリーム生成タスクに対応することができます。モデルは大量の無標識データを用い、自己エンコーディングと自己リカレント任務を組み合わせた预售訓練を行っています。テキスト生成に関連するタスクには、テキスト要約、質問生成、data-to-textなどが含まれます。ここでは、PALMのベースバックボーンモデルを提供していますが、これはダウンストリーム生成タスクのファインチューンに使用できます。
モデルの説明
実際のシーンで一般的であるテキスト生成のニーズに対処するために、独自に開発されたPALM预售訓練言語生成モデルです。このモデルは大規模なテキスト上で预售訓練され、ダウンストリームの自然言語生成タスクのモデルパラメーター入力として使用され、ダウンストリームタスクの生成効果を向上させるのに役立ちます。PALMには以下の特徴があります:
- 理解力が強い:条件付き生成のために特別に設計された预售訓練タスクで、モデルの文脈理解能力が強化されます。
- 必要なアノテーションが少なくなる:モデルは大量のテキスト資料で预售訓練されており、ダウンストリーム生成タスクで必要なラベルデータの量が大幅に減ります。
- パフォーマンスが優れている:中国語と英語のモデルはいずれも大規模なデータでトレーニングされており、NLGタスクに適応した自己開発の预售訓練目標が採用されています。
- 各種の生成タスクに適応可能:PALMは要約、質問生成、paraphrasingなどの異なる生成タスクに使用できます。
- 使いやすい:ダウンストリームでの使用が簡単で、従来のエンコーダーデコーダーフレームワークに基づいています。
このモデルはPALM汎用预售訓練生成モデルであり、すべての中国語生成シーンのトレーニングに使用できます。例えば、data-to-text、要約生成などです。
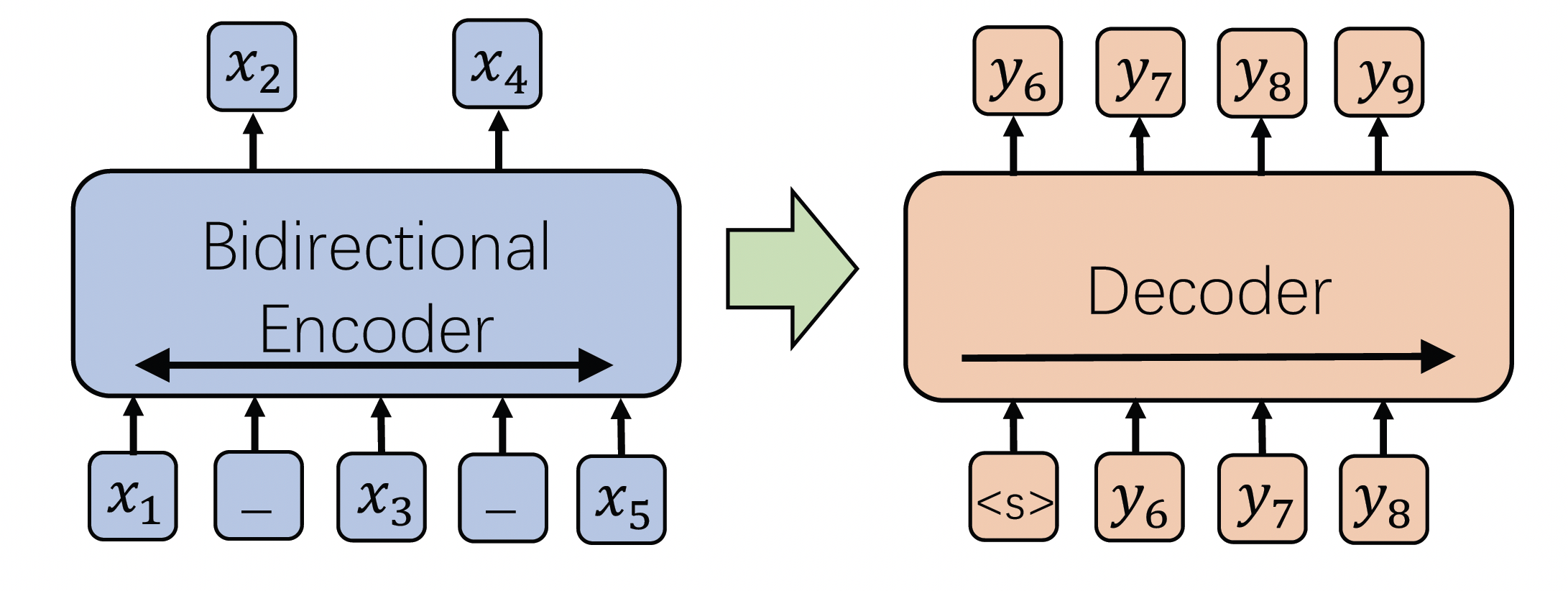
モデルの使用方法と適用範囲
このモデルは主に多様なダウンストリーム生成シナリオに使用されます。ユーザーは独自に生成する入力出力トレーニングデータを構築することができます。具体的な呼び出し方はコードのサンプルを参照してください。
モデルの限界と可能性のあるバイアス
モデルはデータセットでトレーニングされ、バイアスが生じる可能性がありますので、ユーザーは各自評価をしてどのように使用するか決定してください。
トレーニングデータの紹介
このモデルは大量の中国語の無標識データでトレーニングされ、中国語のダウンストリームの複数の生成タスクでSOTAを達成しています。
モデルのトレーニングプロセス
トレーニング
モデルは2つのNVIDIA V100マシンを使用してトレーニングされ、ハイパーパラメーターの設定は以下の通りです。
train_epochs=15
max_sequence_length=128
batch_size=8
learning_rate=1e-3
optimizer=AdamWファインチューンコードのサンプル
import tempfile
from modelscope.msdatasets import MsDataset
from modelscope.metainfo import Trainers
from modelscope.trainers import build_trainer
# DuReader_robust-QG はサンプルデータセットで、ユーザーは自分のデータセットを使用してトレーニングすることもできます。
dataset_dict = MsDataset.load('DuReader_robust-QG')
# トレーニングデータの入力出力はテキストであり、データセットを入力が src_txt、出力が tgt_txt の形式に前処理する必要があります:
train_dataset = dataset_dict['train'].remap_columns({'text1': 'src_txt', 'text2': 'tgt_txt'})
eval_dataset = dataset_dict['validation'].remap_columns({'text1': 'src_txt', 'text2': 'tgt_txt'})
# ユーザー自身のデータセットの構築
# train_dataset_dict = {"src_txt": ["text1", "text2"], "tgt_txt": ["text1", "text2"]}
# eval_dataset_dict = {"src_txt": ["text1", "text2"], "tgt_txt": ["text1", "text2"]}
# train_dataset = MsDataset(Dataset.from_dict(train_dataset_dict))
# eval_dataset = MsDataset(Dataset.from_dict(eval_dataset_dict))
num_warmup_steps = 500
def noam_lambda(current_step: int):
current_step += 1
return min(current_step**(-0.5),
current_step * num_warmup_steps**(-1.5))
# コードでconfigurationの設定を変更することができます
def cfg_modify_fn(cfg):
cfg.train.lr_scheduler = {
'type': 'LambdaLR',
'lr_lambda': noam_lambda,
'options': {
'by_epoch': False
}
}
cfg.train.optimizer = {
"type": "AdamW",
"lr": 1e-3,
"options": {}
}
cfg.train.max_epochs = 15
cfg.train.dataloader = {
"batch_size_per_gpu": 8,
"workers_per_gpu": 1
}
return cfg
kwargs = dict(
model='damo/nlp_palm2.0_pretrained_chinese-base',
train_dataset=train_dataset,
eval_dataset=eval_dataset,
work_dir=tempfile.TemporaryDirectory().name,
cfg_modify_fn=cfg_modify_fn)
trainer = build_trainer(
name=Trainers.text_generation_trainer, default_args=kwargs)
trainer.train()トレーニングのヒント
ハイパーパラメーターの調整は主にlrとepochで、cfg_modify_fnで変更することができます。
生成するデータセットの長さが短い場合は、トレーニングのラウンドを10~20epoch程度に小さくすることができますが、生成するデータセットの長さが長い場合は30~50epochなど多くのラウンドが必要です。
生成する必要のあるデータセットの量は大きいですが、タスクが簡単な場合は1w~10wで十分かもしれませんが、生成が難し目のタスクの場合はより多くのデータが必要です。
会社名:株式会社Dolphin AI

事業内容:
DolphinSOE 英語発音評価サービスの開発&販売
DolphinVoice 音声対話SaaS Platformの開発&販売
アクセス情報:〒170-0013
東京都豊島区東池袋1-18-1 Hareza Tower 20F
JR山手線・埼京線 池袋駅東口(30番出口)より徒歩4分
東京メトロ丸の内線・副都心線・有楽町線 池袋駅東口(30番出口)より徒歩4分
西武池袋線 池袋駅東口(30番出口)より徒歩4分
東武東上線 池袋駅東口(30番出口)より徒歩4分
電話番号:(+81) 03-6775-4523
メールアドレス:contact@dolphin-ai.jp

