SenseVoiceは高精度の多言語音声認識、感情認識、および音響イベント検出に特化しています。
多言語認識:40万時間以上のデータで訓練され、50以上の言語をサポートし、Whisperモデルを上回る認識効果を実現しています。
富文本認識:優れた感情認識能力があり、テストデータで現在の最良の感情認識モデルと同等以上の効果を達成できます。
音声イベント検出能力をサポートしています。音楽、拍手、笑い、泣き、咳、くしゃみなど、一般的な人間と機械の相互作用イベントを検出できます。
高効率推論:SenseVoice-Smallモデルは非自帰的エンドツーエンドフレームワークを使用しており、推論遅延が非常に低く、10秒のオーディオ推論はわずか70msで、Whisper-Largeを15倍優位です。
ファインチューニングカスタマイズ:便利なファインチューニングスクリプトと戦略が用意されており、ユーザーはビジネスシナリオに基づいてロングテールサンプルの問題を簡単に修正できます。
サービスデプロイ:完全なサービスデプロイメントチェーンルがあり、マルチコンカレントリクエストをサポートし、Python、C++、HTML、Java、C#などのクライアント言語をサポートしています。
SenseVoiceオープンソースプロジェクトの紹介
SenseVoiceオープンソースモデルは多言語音声理解モデルで、音声認識、語種認識、音声感情認識、音響イベント検出能力が含まれています。
モデル構造図
SenseVoice多言語音声理解モデルは、音声認識、語種認識、音声感情認識、音響イベント検出、逆テキスト正規化などの能力をサポートし、産業レベルの数十万時間の注釈付きオーディオを使用してモデルを訓練し、モデルの汎用認識効果を保証しています。モデルは中国語、広東語、英語、日本語、韓国語の音声認識に適用され、感情とイベントを含む富文本転写結果を出力できます。
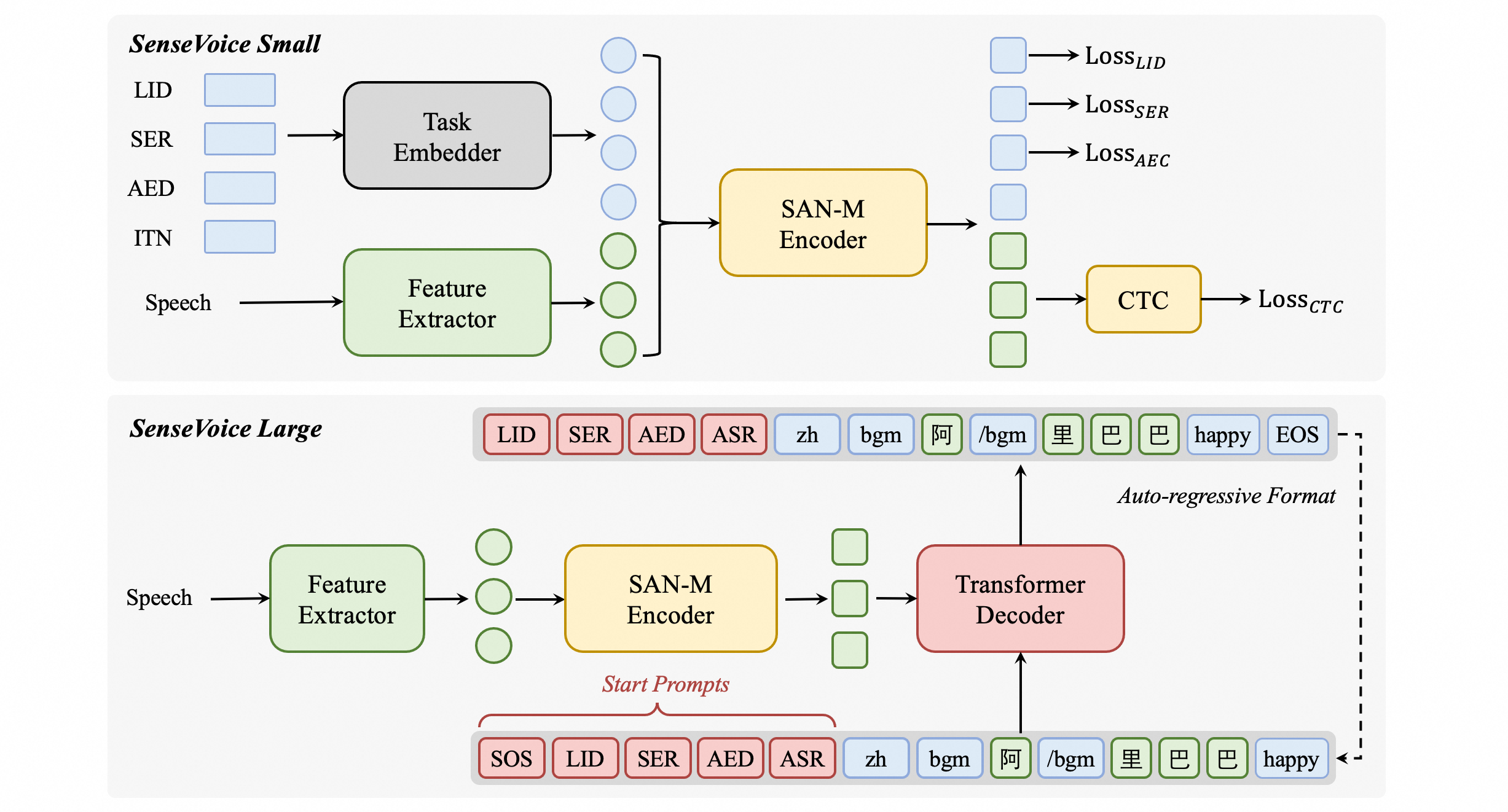
SenseVoiceモデル構造
SenseVoice-Smallは非自帰的エンドツーエンドフレームワークモデルに基づいており、特定のタスクのために、私たちは音声特徴の前に4つの埋め込みを追加し、エンコーダーに渡します。
LID:オーディオ言語タグを予測するために使用されます。
SER:オーディオ感情タグを予測するために使用されます。
AED:オーディオに含まれるイベントタグを予測するために使用されます。
ITN:認識出力テキストが逆テキスト正規化を行うかどうかを指定するために使用されます。
依存環境
推論前に、funasrおよびmodelscopeのバージョンを更新してください。
pip install -U funasr modelscope使用方法
推論
modelscope pipeline推論
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
inference_pipeline = pipeline(
task=Tasks.auto_speech_recognition,
model='iic/SenseVoiceSmall',
model_revision="master",
device="cuda:0",)
rec_result = inference_pipeline('https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav')
print(rec_result)funasrを使用した推論
任意のフォーマットのオーディオ入力をサポートし、任意の長さの入力をサポートしています。
from funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
model = AutoModel(
model=model_dir,
trust_remote_code=True,
remote_code="./model.py",
vad_model="fsmn-vad",
vad_kwargs={"max_single_segment_time": 30000},
device="cuda:0",
)
# en
res = model.generate(
input=f"{model.model_path}/example/en.mp3",
cache={},
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size_s=60,
merge_vad=True, #
merge_length_s=15,
)
text = rich_transcription_postprocess(res[0]["text"])
print(text)パラメーター説明:
model_dir:モデル名、またはローカルディスクのモデルパス。
trust_remote_code:
Trueは、modelコード実装がremote_codeからロードされることを示し、remote_codeはmodel具体コードの位置を指定します(例:現在のディレクトリのmodel.py)、サポートは絶対パスおよび相対パス、ネットワークurl。
Falseは、modelコード実装がFunASR内部統合バージョンであることを示し、この場合、現在のディレクトリのmodel.pyの変更は有効になりません。読み込まれるのはfunasr内部バージョンです。モデルコードを確認するにはここをクリックしてください。
vad_model:VADを有効にすることを示します。VADの役割は、長いオーディオを短いオーディオに切り分けることで、この場合の推論時間はVADとSenseVoiceの合計時間であり、リンク時間です。SenseVoiceモデルの時間を個別にテストする必要がある場合は、VADモデルをオフにすることができます。
vad_kwargs:VADモデルの設定を示し、max_single_segment_time:vad_modelが最大でオーディオを切り分ける時間、単位はミリ秒ms。
use_itn:出力結果に句読点と逆テキスト正規化を含めるかどうかを示します。
batch_size_s は動的バッチを使用し、バッチ内の総オーディオ時間、単位は秒s。
merge_vad:vadモデルが切り分けた短いオーディオフラグメントを合成するかどうかを示し、合成後の長さはmerge_length_s、単位は秒s。
ban_emo_unk:emo_unkタグを無効にします。無効にすると、すべての文章に感情タグが割り当てられます。デフォルトはFalse
model = AutoModel(model=model_dir, trust_remote_code=True, device="cuda:0")
res = model.generate(
input=f"{model.model_path}/example/en.mp3",
cache={},
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size=64,
)
モデルダウンロード
上記のコードは自動的にモデルをダウンロードしますが、オフラインでモデルをダウンロードする必要がある場合は、以下のコードを使用して手動でダウンロードし、その後ローカルパスを指定してください。
SDKダウンロード
ModelScopeをインストール
pip install modelscope
SDKモデルダウンロード
from modelscope import snapshot_download
model_dir = snapshot_download('iic/SenseVoiceSmall')
Gitダウンロード
Gitモデルダウンロード
git clone https://www.modelscope.cn/iic/SenseVoiceSmall.git
サービスデプロイ
Undo
パフォーマンス
音声認識効果
私たちは、SenseVoiceとWhisperの多言語音声認識性能と推論効率を比較するために、オープンソースのベンチマークデータセット(AISHELL-1、AISHELL-2、Wenetspeech、Librispeech、Common Voiceを含む)を使用しました。中国語と広東語の認識効果で、SenseVoice-Smallモデルは明らかな効果の優位性があります。
SenseVoiceモデルのオープンソーステストセットでのパフォーマンス
感情認識効果
現在、広く使用される感情認識テスト指標とメソッドが乏しいため、私たちは多くのテストセットで多くの指標をテストし、近年のベンチマークの多くの結果と全面的な比較をしました。選択されたテストセットは中国語/英語の両方を含むほか、パフォーマンス、テレビドラマ、自然対話など多くのスタイルのデータが含まれています。目標データのファインチューニングを行わない前提で、SenseVoiceはテストデータで現在の最良の感情認識モデルと同等以上の効果を達成できます。
SenseVoiceモデルSER効果1
また、私たちはテストセットで多くのオープンソース感情認識モデルを比較し、その結果、SenseVoice-Largeモデルはほぼすべてのデータで最良の効果を達成し、SenseVoice-Smallモデルも他のオープンソースモデルを上回る効果をもたらすことができます。
SenseVoiceモデルSER効果2
イベント検出効果
SenseVoiceは音声データだけを使用して訓練されていますが、それは依然としてイベント検出モデルとして個別に使用できます。私たちは環境音分類ESC-50データセットで、現在業界で広く使用されているBEATSとPANNモデルの効果と比較しました。SenseVoiceモデルはこれらのタスクで良い効果を達成できますが、訓練データと訓練方法の制限により、専門のイベント検出モデルと比較してイベント分類効果にはまだ一定のギャップがあります。
会社名:株式会社Dolphin AI

事業内容:
Dolphin SOE 英語発音評価サービスの開発&販売
Dolphin Voice 音声対話SaaS Platformの開発&販売
ドルフィンAIは自社開発のAI技術を持つ研究開発型のハイテク企業です。
独自技術の音声対話意図理解モデル(Dolphin Large Language Models)に基づき、音声認識、音声生成、意味理解、テキスト生成、機械翻訳、声紋認識、その他音声対話のフルチェーン技術を開発し、日本語、英語、中国語、韓国語、フランス語、スペイン語、ロシア語、ドイツ語、チベット語、タイ語、ベトナム語など20以上の言語に対応しています。
また、SaaSやオンプレミスのサービス形態を通じて、教育、医療、金融、その他の分野のお客様に基礎となるAI技術と業界ソリューションを提供しています。
アクセス情報:〒170-0013
東京都豊島区東池袋1-18-1 Hareza Tower 20F
JR山手線・埼京線 池袋駅東口(30番出口)より徒歩4分
東京メトロ丸の内線・副都心線・有楽町線 池袋駅東口(30番出口)より徒歩4分
西武池袋線 池袋駅東口(30番出口)より徒歩4分
東武東上線 池袋駅東口(30番出口)より徒歩4分
電話番号:(+81) 03-6775-4523
メールアドレス:contact@dolphin-ai.jp