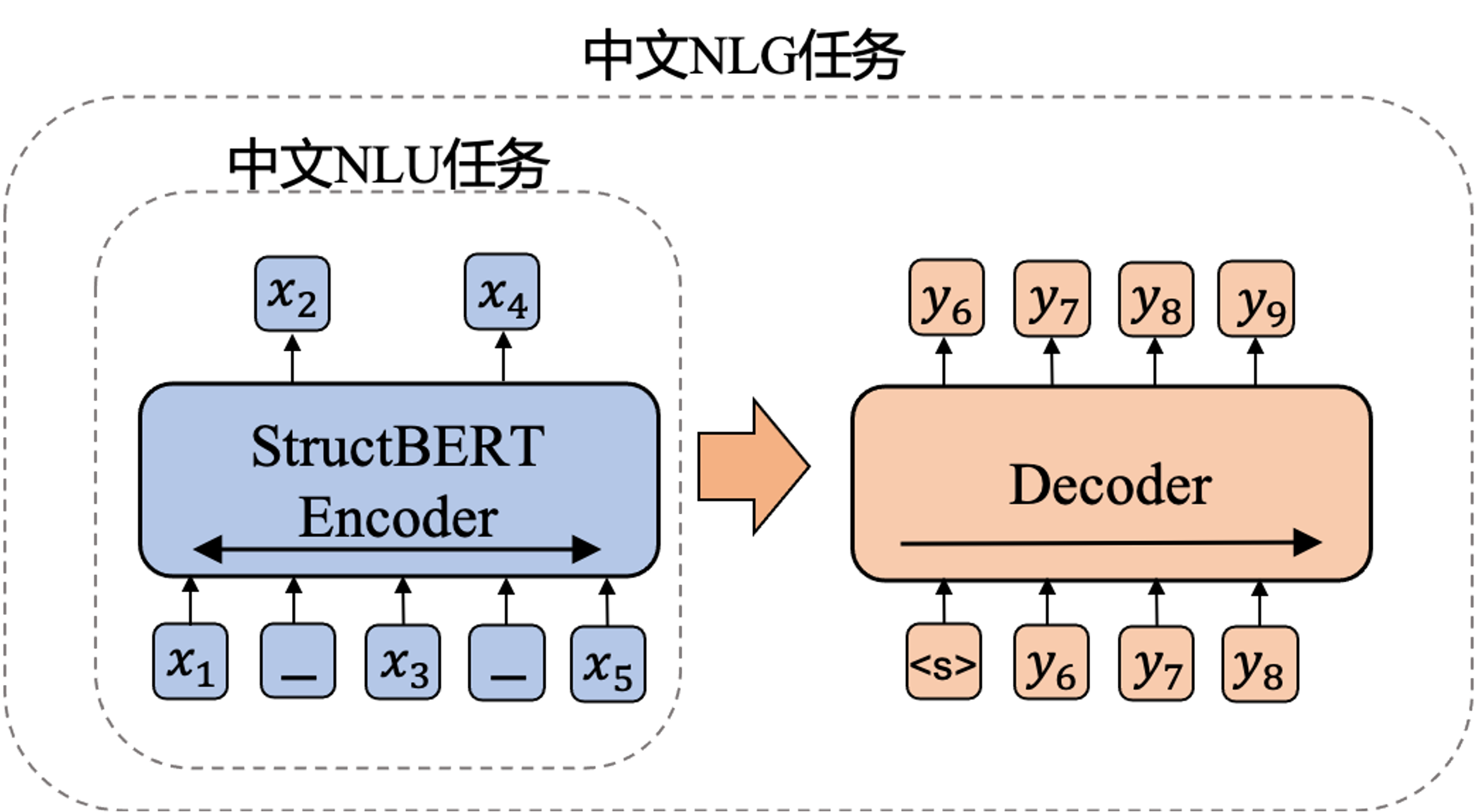
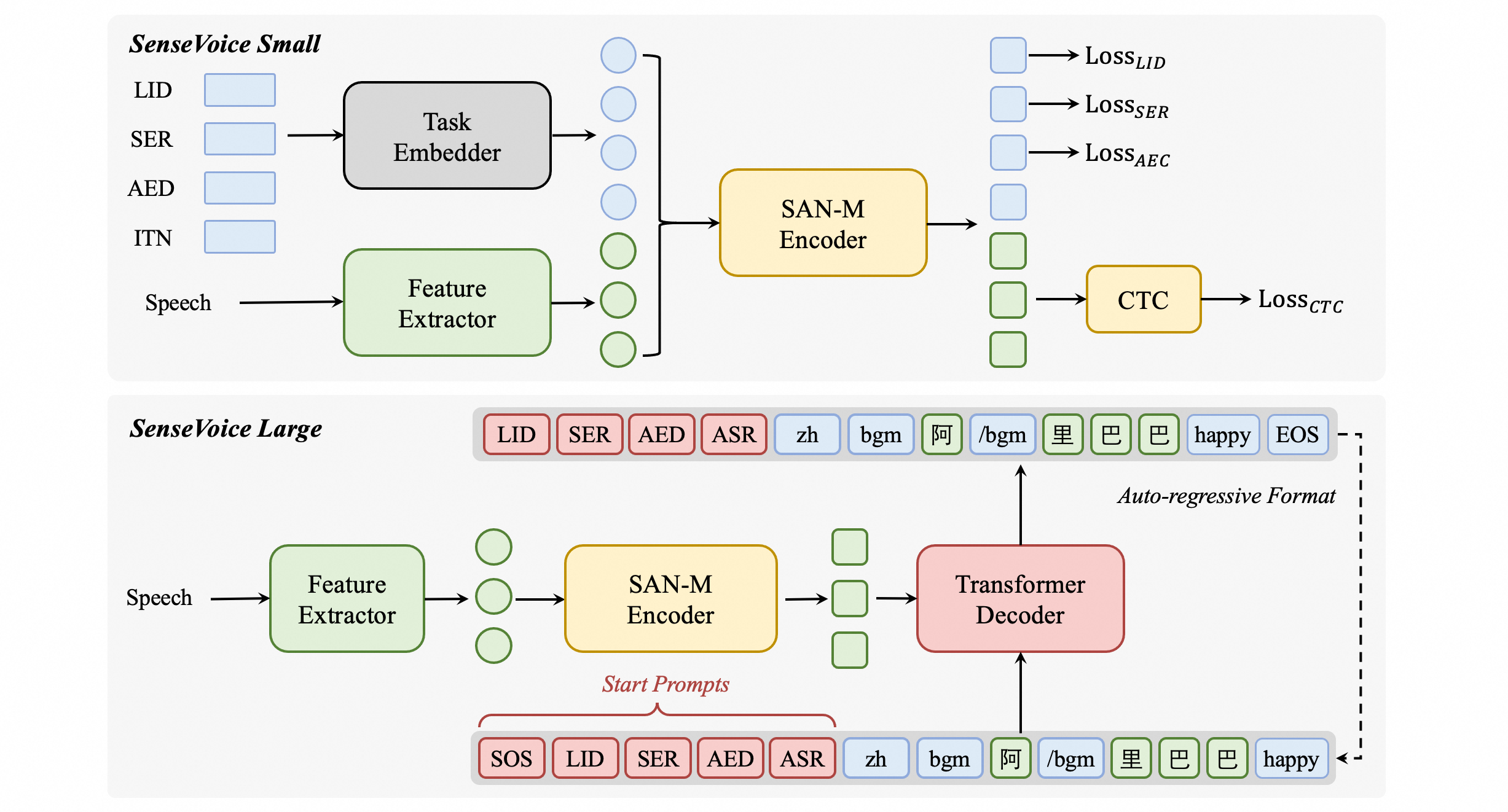
Paraformer-largeモデルの紹介
ハイライト
Paraformer-largeホットワード版モデルはホットワードカスタマイズ機能をサポートしています:ホットワードリストに基づいてインセンティブを強化し、ホットワードのリコール率と正確さを向上させることができます。
FunASRオープンソースプロジェクトの紹介
FunASRは、音声認識の学術研究と産業応用とを架け橋になりたいと考えています。産業レベルの音声認識モデルのトレーニングとファインチューニングを公開することで、研究者や開発者は音声認識モデルの研究と実践をより簡単に行え、音声認識の生態系の発展を促進させることができます。音声認識をもっと面白く!
モデルの原則の紹介
SeACoParaformerは、アリババの音声研究所が提案した次世代のホットワードカスタマイズ非自帰的音声認識モデルです。以前のCLASに基づくホットワードカスタマイズソリューションとは異なり、SeACoParaformerはホットワードモジュールとASRモデルを解耦し、ポスターイオリプロバビリティの融合によってホットワードのインセンティブを行っています。これにより、インセンティブプロセスが可視・可管理になり、ホットワードのリコール率が著しく向上します。
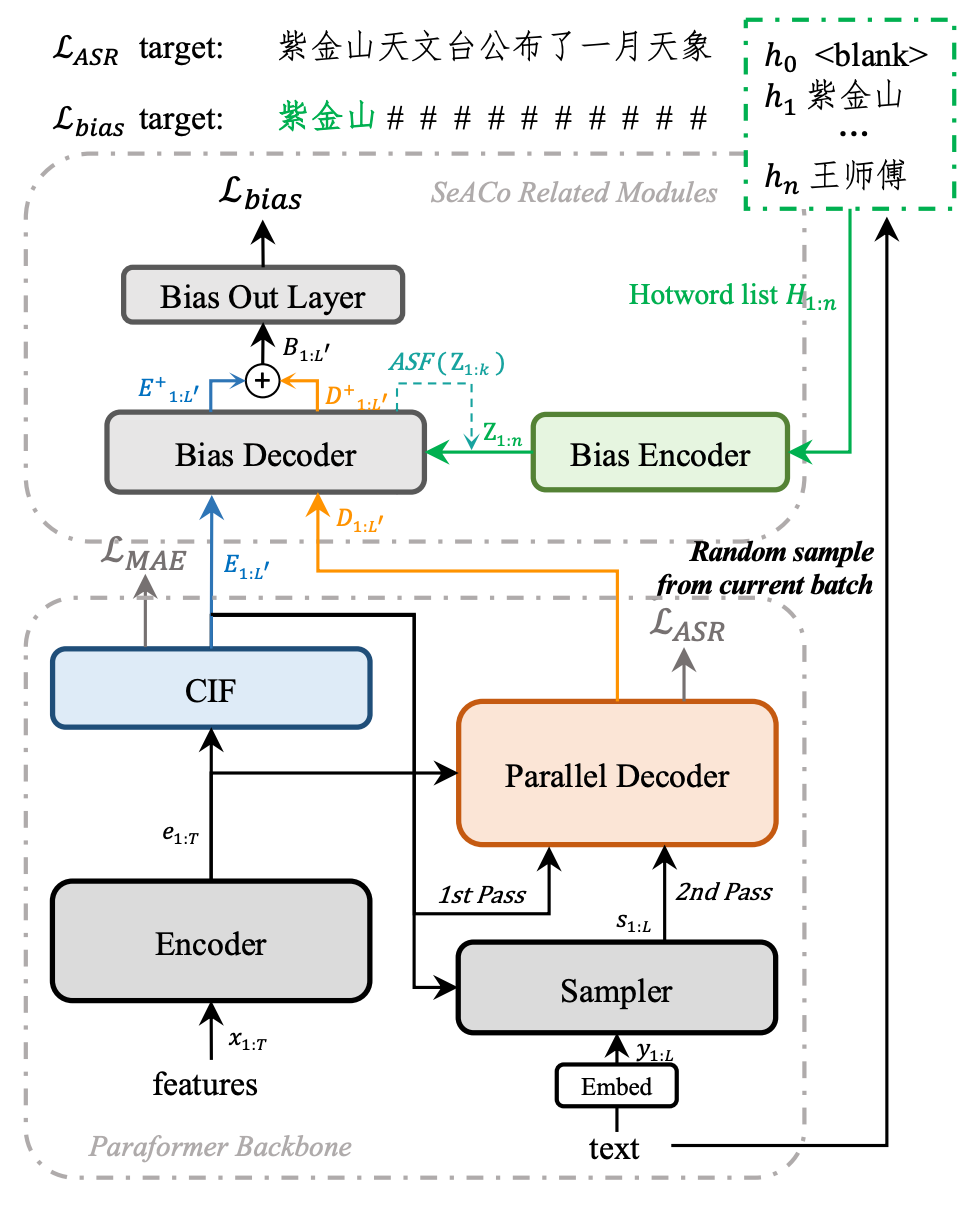
SeACoParaformerモデルの構造
SeACoParaformerのモデル構造とトレーニングプロセスは上記の図に示されています。バイアスエンコーダーを介してホットワードの埋め込みを抽出し、バイアスデコーダーを介して注意モデルを行い、SeACoParaformerはPredictorの出力とDecoderの出力の情報とホットワードの関連性を捉え、ASR結果と同期したホットワードの出力を予測することができます。ポスターイオリプロバリティの融合を通じて、ホットワードのインセンティブを実現しています。ContextualParaformerと比較すると、SeACoParaformerは明らかに効果が向上していますが、以下に示します:

より詳細な詳細については以下を参照してください:
論文:SeACo-Paraformer: A Non-Autoregressive ASR System with Flexible and Effective Hotword Customization Ability
論文の結果を再現
from funasr import AutoModel
model = AutoModel(model="iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch",
model_revision="v2.0.4",
# vad_model="damo/speech_fsmn_vad_zh-cn-16k-common-pytorch",
# vad_model_revision="v2.0.4",
# punc_model="damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch",
# punc_model_revision="v2.0.4",
# spk_model="damo/speech_campplus_sv_zh-cn_16k-common",
# spk_model_revision="v2.0.2",
device="cuda:0"
)
res = model.generate(input="YOUR_PATH/aishell1_hotword_dev.scp",
hotword='./data/dev/hotword.txt',
batch_size_s=300,
)
fout1 = open("dev.output", 'w')
for resi in res:
fout1.write("{}\t{}\n".format(resi['key'], resi['text']))
res = model.generate(input="YOUR_PATH/aishell1_hotword_test.scp",
hotword='./data/test/hotword.txt',
batch_size_s=300,
)
fout2 = open("test.output", 'w')
for resi in res:
fout2.write("{}\t{}\n".format(resi['key'], resi['text']))ModelScopeを用いた推論
推論がサポートするオーディオフォーマットは以下の通りです:
wavファイルパス、例:data/test/audios/asr_example.wav
pcmファイルパス、例:data/test/audios/asr_example.pcm
wavファイルurl、例:https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav
wavバイナリデータ、フォーマットbytes、例:ユーザーが直接ファイルからbytesデータを読み出したり、マイクからbytesデータを録音したりする。
パース済のaudioオーディオ、例:audio, rate = soundfile.read("asr_example_zh.wav")、タイプはnumpy.ndarrayまたはtorch.Tensor。
wav.scpファイル、以下のように要求されます:
cat wav.scp
asr_example1 data/test/audios/asr_example1.wav
asr_example2 data/test/audios/asr_example2.wav
...
入力形式がwavファイルurlの場合、APIの呼び出し方法は以下の例を参照してください:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
inference_pipeline = pipeline(
task=Tasks.auto_speech_recognition,
model='iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch', model_revision="v2.0.4")
rec_result = inference_pipeline('https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav', hotword='達磨院 魔討')
print(rec_result)入力オーディオがpcmフォーマットの場合、APIの呼び出し時にオーディオサンプリングレートパラメーターaudio_fsを渡す必要があります、例:
rec_result = inference_pipeline('https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.pcm', fs=16000, hotword='達磨院 魔討')入力オーディオがwavフォーマットの場合、APIの呼び出し方法は以下の例を参照してください:
rec_result = inference_pipeline('asr_example_zh.wav', hotword='達磨院 魔討')入力形式がファイルwav.scp(注:ファイル名は.scpで終わる必要があります)の場合、認識結果をファイルに書き込むためにoutput_dirパラメーターを追加できます、APIの呼び出し方法は以下の例を参照してください:
inference_pipeline("wav.scp", output_dir='./output_dir', hotword='達磨院 魔討')認識結果の出力パス構造は以下の通りです:
tree output_dir/
output_dir/
└── 1best_recog
├── score
└── text
1 directory, 3 files
score:認識パススコア
text:音声認識結果ファイル
入力オーディオがパース済のaudioオーディオの場合、APIの呼び出し方法は以下の例を参照してください:
import soundfile
waveform, sample_rate = soundfile.read("asr_example_zh.wav")
rec_result = inference_pipeline(waveform, hotword='達磨院 魔討')ASR、VAD、PUNCモデルの自由な組み合わせ
使用ニーズに基づいてVADとPUNC句読点モデルを自由に組み合わせることができます、使用方法は以下の通りです:
inference_pipeline = pipeline(
task=Tasks.auto_speech_recognition,
model='iic/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch', model_revision="v2.0.4",
vad_model='iic/speech_fsmn_vad_zh-cn-16k-common-pytorch', vad_model_revision="v2.0.4",
punc_model='iic/punc_ct-transformer_zh-cn-common-vocab272727-pytorch', punc_model_revision="v2.0.3",
# spk_model="iic/speech_campplus_sv_zh-cn_16k-common",
# spk_model_revision="v2.0.2",
)PUNCモデルを使わない場合は、punc_model=Noneを設定するか、punc_modelパラメーターを渡さないでください。LMモデルを加えたい場合は、lm_model='iic/speech_transformer_lm_zh-cn-common-vocab8404-pytorch'を追加設定し、lm_weightとbeam_sizeパラメーターを設定してください。
FunASRを用いた推論
以下は、テストオーディオ(中国語、英語)のクイックスタートガイドです。
実行可能なコマンドライン
コマンドライン端末で実行:
funasr +model=paraformer-zh +vad_model="fsmn-vad" +punc_model="ct-punc" +input=vad_example.wav注:シングルオーディオファイルの認識をサポートし、ファイルリストもサポートしています。リストはkaldi
会社名:株式会社Dolphin AI

事業内容:
Dolphin SOE 英語発音評価サービスの開発&販売
Dolphin Voice 音声対話SaaS Platformの開発&販売
ドルフィンAIは自社開発のAI技術を持つ研究開発型のハイテク企業です。
独自技術の音声対話意図理解モデル(Dolphin Large Language Models)に基づき、音声認識、音声生成、意味理解、テキスト生成、機械翻訳、声紋認識、その他音声対話のフルチェーン技術を開発し、日本語、英語、中国語、韓国語、フランス語、スペイン語、ロシア語、ドイツ語、チベット語、タイ語、ベトナム語など20以上の言語に対応しています。
また、SaaSやオンプレミスのサービス形態を通じて、教育、医療、金融、その他の分野のお客様に基礎となるAI技術と業界ソリューションを提供しています。
アクセス情報:〒170-0013
東京都豊島区東池袋1-18-1 Hareza Tower 20F
JR山手線・埼京線 池袋駅東口(30番出口)より徒歩4分
東京メトロ丸の内線・副都心線・有楽町線 池袋駅東口(30番出口)より徒歩4分
西武池袋線 池袋駅東口(30番出口)より徒歩4分
東武東上線 池袋駅東口(30番出口)より徒歩4分
電話番号:(+81) 03-6775-4523
メールアドレス:contact@dolphin-ai.jp