大規模な中国語理解と生成の共同モデル PLUG
PLUG (言語理解と生成のための事前トレーニング) は、中国語の理解と生成のための 270 億パラメータの大規模な共同事前トレーニング モデルです。
モデルの説明
PLUG は、大量の高品質の中国語テキストで事前トレーニングされた共同理解および生成モデルです。 PLUG トレーニングは 2 つのフェーズで構成されます。最初に 24 層の StructBERT ベースのエンコーダをトレーニングし、次にこれに基づいて 24+6 層の PALM エンコーダ/デコーダをトレーニングしました。これにより、モデルは、自然言語生成 (NLG) タスクだけでなく、微調整によるテキスト分類やシーケンスの注釈などの自然言語理解 (NLU) タスクを処理できるようになります。
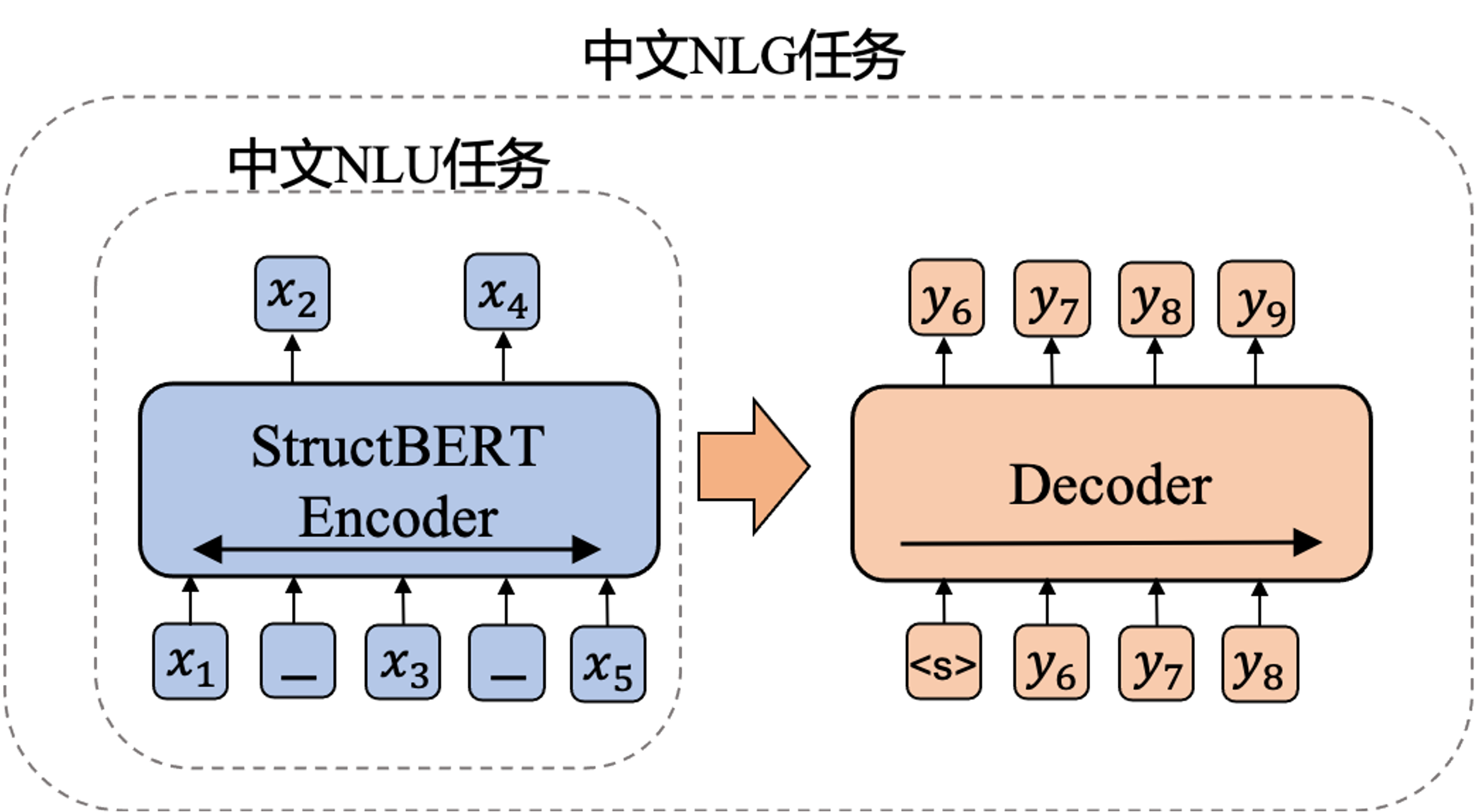
このモデルはテキスト生成に直接使用でき、fine-tuningを通じて様々なテキスト理解のタスクにも使用できます。ユーザーは様々な入力文書を試してみることができます。具体的な呼び出し方法については、コードのサンプルを参照してください。
使用方法
ModelScope-libをインストールすると、PLUGの能力を使用できます。
依存インストール
PLUGモデルに依存するMegatron関連のコードを個別のパッケージにパッケージ化しましたが、以下のコマンドでインストールできます:
pip install megatron_util -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.htmlコードの例
このサンプルはシングルマシン8カード(GPU)の例であり、実行時には各GPUが約12Gのメモリを使用します。
model_idを使用してデフォルトのmodel_dirを取得
from modelscope.hub.snapshot_download import snapshot_download
model_id = 'damo/nlp_plug_text-generation_27B'
model_dir = snapshot_download(model_id)
print(model_dir)モデルのバイナリファイルをmodel_dir/modelにダウンロードします。ダウンロード先のURLは以下から取得できます:https://github.com/alibaba/AliceMind/tree/main/PLUG#pre-trained-model-download
モデルの呼び出し
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
if __name__ == '__main__':
input = '段誉轻挥折扇,摇了摇头,说道:“你师父是你的师父,你师父可不是我的师父。"'
model_id = 'damo/nlp_plug_text-generation_27B'
pipe = pipeline(Tasks.text_generation, model=model_id)
pipe.models = []
# out_lengthは生成される長さを望む長さで、最大512
result = pipe(input, out_length=256)
print(result)モデルの限界および可能性のある偏差
モデルの訓練データは限定的であり、結果に一定の偏差が存在する可能性があります。
会社名:株式会社Dolphin AI

事業内容:
DolphinSOE 英語発音評価サービスの開発&販売
DolphinVoice 音声対話SaaS Platformの開発&販売
アクセス情報:〒170-0013
東京都豊島区東池袋1-18-1 Hareza Tower 20F
JR山手線・埼京線 池袋駅東口(30番出口)より徒歩4分
東京メトロ丸の内線・副都心線・有楽町線 池袋駅東口(30番出口)より徒歩4分
西武池袋線 池袋駅東口(30番出口)より徒歩4分
東武東上線 池袋駅東口(30番出口)より徒歩4分
電話番号:(+81) 03-6775-4523
メールアドレス:contact@dolphin-ai.jp