タイトル:GPT-3テキスト生成モデルの紹介
モデルの説明
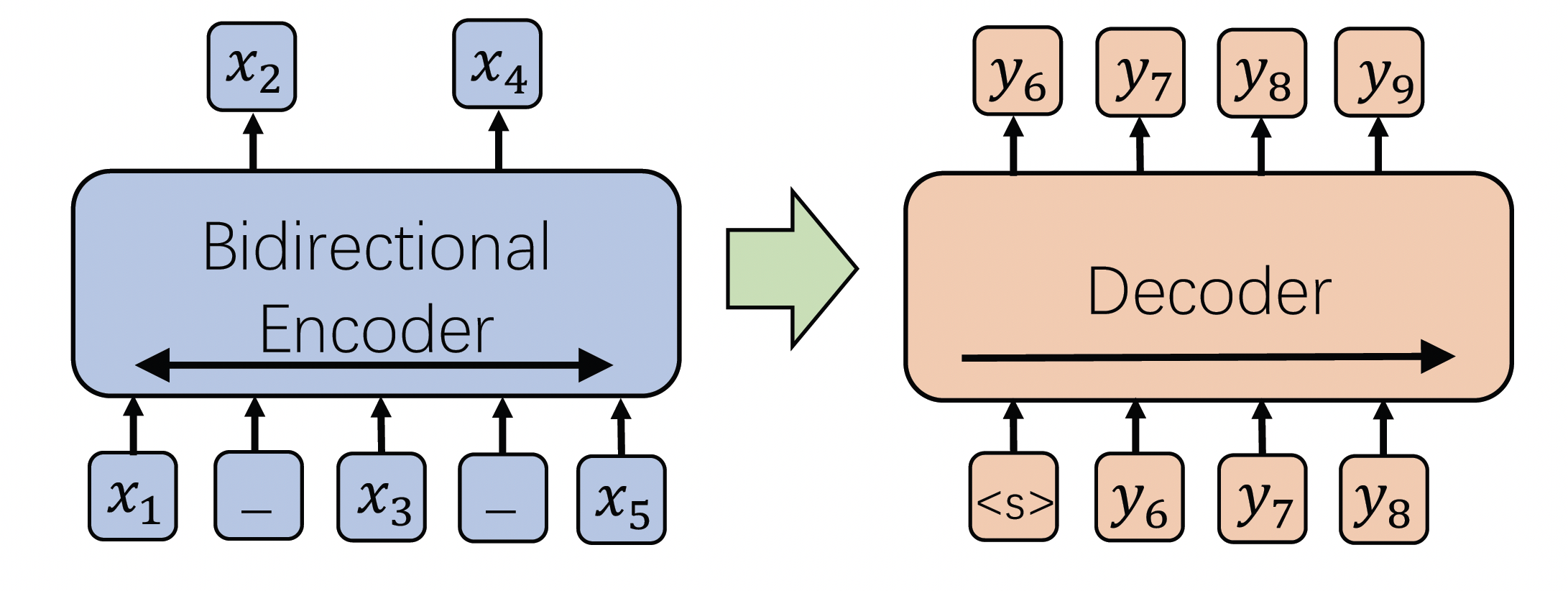
GPT-3モデルは、一般的な预售訓練生成モデルで、TransformerのDecoder-only構造を使用しています。これはダウンストリームの様々な生成タスク、特にzero-shot生成能力に役立ちます。モデルは大量の無標識データを用いて、自帰帰的任務を通じて预售訓練されます。テキスト生成に関連するタスクには、テキスト要約、質問生成、data-to-textなどが含まれます。

日本語でのモデル説明
GPT-3モデルはTransformerのDecoder構造を使い、いくつかの変更を加えています。本来のDecoderには2つのMulti-Head Attention構造が含まれていますが、GPT-3はMask Multi-Head Attentionだけを残しました。通常の言語モデリングの最適化を通じて、左から右への自帰帰的预售訓練を行います。このモデルはGPT-3のコードをベースに、中国語の無標識データとダウンストリームタスクデータを組み合わせて预售訓練され、さまざまなパラメーターのモデルをトレーニングしましたが、ここではGPT-3 Largeモデルを紹介します。
このプロジェクトでは、異なる規模の中国語GPT3モデルのシリーズを再現しましたが、base/large/1.3B/2.7B/13B/30B/175Bなど、このモデルはそのlargeバージョンです。すべてのバージョンは以下の表の通りです。
| モデル | レイヤー | ヘッド | d_model | LR | バッチ |
|---|---|---|---|---|---|
| base | 12 | 12 | 768 | 6.0e-4 | 0.5M |
| large | 24 | 16 | 1024 | 3.0e-4 | 0.5M |
| 1.3B | 24 | 32 | 2048 | 2.0e-4 | 2M |
| 2.7B | 32 | 32 | 2560 | 1.6e-4 | 2M |
| 13B | 40 | 40 | 5120 | 1.0e-4 | 6M |
| 30B | 48 | 56 | 7168 | 1.0e-4 | 6M |
| 175B(進行中) | 96 | 96 | 12288 | 1.2e-4 | 6M |
モデルの使用方法と適用範囲
このモデルは主に多様なシーンでの入力に基づく生成と続きを書くことに使われます。例えば、ユーザーはさまざまなコンテンツを入力して、モデルが回答したり、続きを書いたり、命令に応じて返信したりすることができます。
使用方法
ModelScope libraryをインストールすると、GPT-3のテキスト生成能力が使用可能になります。
コードの例
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
text_generation_zh = pipeline(Tasks.text_generation, model='damo/nlp_gpt3_text-generation_chinese-large')
result_zh = text_generation_zh("コンピュータビジョンが急速に発展するにつれ、顔認識技術は単純なシーンから複雑なシーンに発展し、ポーズ、照明、表情、ノイズ、遮蔽、化粧、年齢、人種、性別などの相違が表れた複雑なシーンです。既存の顔認識システムは特定の制約環境で高い認識成功率を示していますが、")
print(result_zh['text'])モデルの限界と可能性のあるバイアス
モデルはデータセットでトレーニングされ、バイアスが生じる可能性がありますので、ユーザーは各自評価をしてどのように使用するか決定してください。
トレーニングデータの紹介
トレーニングデータには、中国語のウィキペディアやインターネット上の公開テキストデータが含まれています。
モデルのトレーニングプロセス
前処理
トレーニングデータはsrc_txtフィールドのみを含むことが推奨され、MsDatasetを使用してModelScopeのTrainerでトレーニングします。
トレーニング
以下は、GPT-3中国語largeモデルを基に诗词生成データセットで二次開発トレーニングします。
トレーニングのヒント
トレーニングlrは上記の表の異なるモデルの設定を参考に設定できます。トレーニングデータが長い場合は、トレーニングepochを適宜増やしてください。
会社名:株式会社Dolphin AI

事業内容:
DolphinSOE 英語発音評価サービスの開発&販売
DolphinVoice 音声対話SaaS Platformの開発&販売
アクセス情報:〒170-0013
東京都豊島区東池袋1-18-1 Hareza Tower 20F
JR山手線・埼京線 池袋駅東口(30番出口)より徒歩4分
東京メトロ丸の内線・副都心線・有楽町線 池袋駅東口(30番出口)より徒歩4分
西武池袋線 池袋駅東口(30番出口)より徒歩4分
東武東上線 池袋駅東口(30番出口)より徒歩4分
電話番号:(+81) 03-6775-4523
メールアドレス:contact@dolphin-ai.jp