GPT-3テキスト生成モデルの紹介
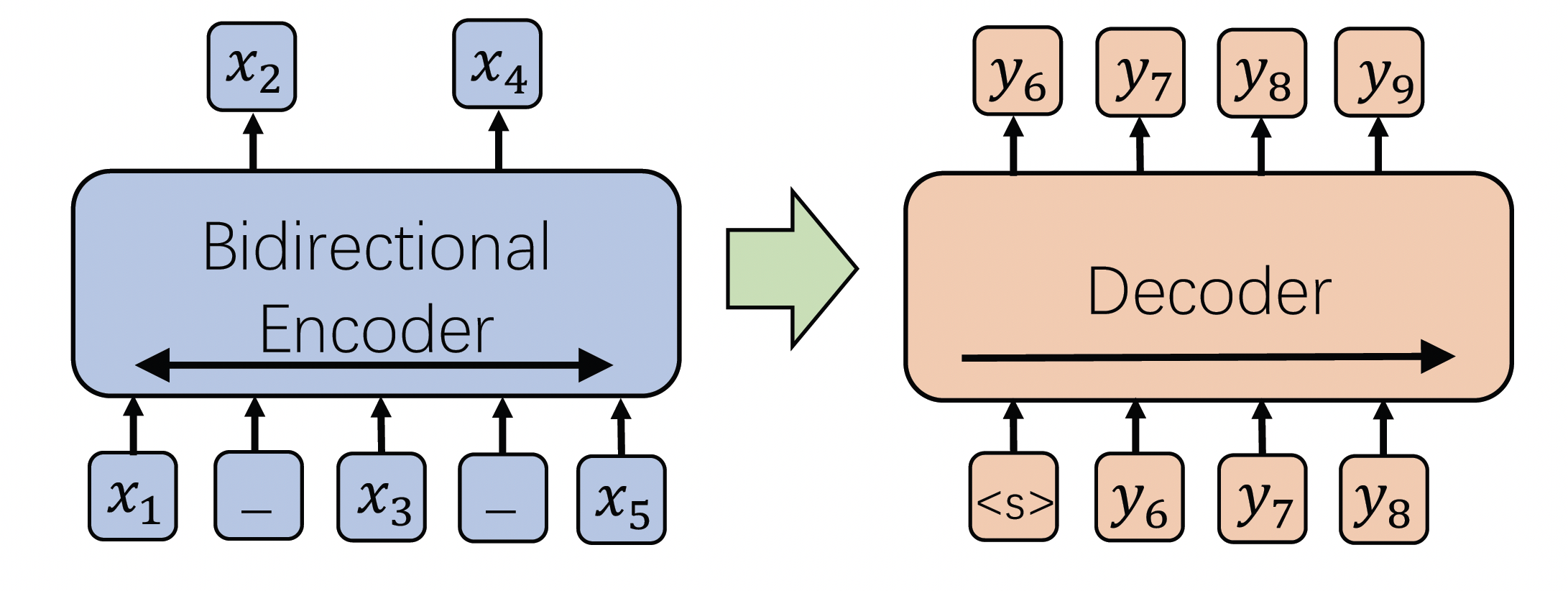
GPT-3モデルは汎用的な预售訓練生成モデルで、TransformerのDecoder-only構造を採用しています。これはzero-shot生成能力を含む様々なダウンストリームの生成タスクに使用できます。モデルは大量の無標識データを使用して、自己リカレントタスクを通じて预售訓練されます。テキスト生成に関連するタスクには、テキスト要約、質問生成、data-to-textなどが含まれます。
モデルの説明:
GPT-3モデルはTransformerのDecoder構造を使用し、Transformer Decoderにいくつかの変更を加えました。元のDecoderには2つのMulti-Head Attention構造が含まれていますが、GPT-3はMask Multi-Head Attentionだけを残しました。通常の言語モデリングの最適化を通じて、左から右への自己リカレント预售訓練を行います。このモデルはGPT-3のコードをベースに、大量の中国語の無標識データとダウンストリームタスクデータを組み合わせて预售訓練されました。ここでは、GPT-3 Baseモデルの複数パラメーターのモデルをトレーニングしました。GPT-3モデルの詳細については、「Language Models are Few-Shot Learners」を参照してください。
このプロジェクトでは、スケールの異なる中国語GPT3モデルのシリーズを再現しました。これにはbase/large/1.3B/2.7B/13B/30B/175Bなどが含まれます。ここでは、その中のbaseバージョンのモデルを紹介します。すべてのバージョンは以下の表に示されています。

モデルの使用目的と適用範囲
このモデルは主に多様なシーンでの入力に基づく生成と続きを書くことに使われます。例えば、ユーザーは様々な内容を入力して、モデルに回答させたり、続きを書かせたり、命令に応じて返信させることができます。
使用方法
ModelScopeライブラリをインストールした後、GPT-3のテキスト生成機能を使用することができます。
会社名:株式会社Dolphin AI

事業内容:
DolphinSOE 英語発音評価サービスの開発&販売
DolphinVoice 音声対話SaaS Platformの開発&販売
アクセス情報:〒170-0013
東京都豊島区東池袋1-18-1 Hareza Tower 20F
JR山手線・埼京線 池袋駅東口(30番出口)より徒歩4分
東京メトロ丸の内線・副都心線・有楽町線 池袋駅東口(30番出口)より徒歩4分
西武池袋線 池袋駅東口(30番出口)より徒歩4分
東武東上線 池袋駅東口(30番出口)より徒歩4分
電話番号:(+81) 03-6775-4523
メールアドレス:contact@dolphin-ai.jp